The Concept
CASE is based on a simple idea:
To understand the meaning of a GPA, two types of information are necessary:
How does a degree compare to other students in the same program?
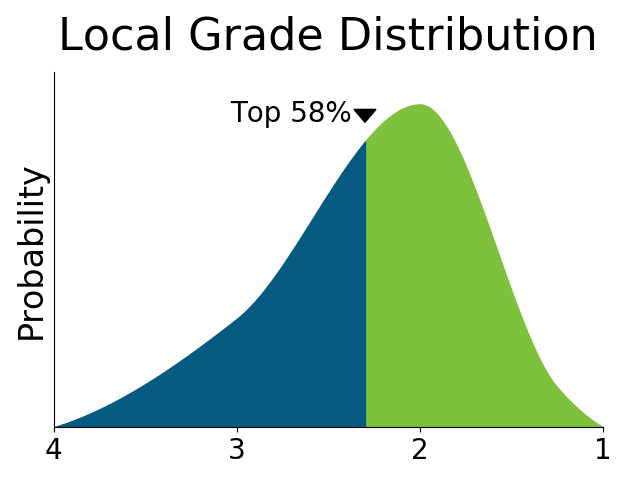
How are students in the program graded? Depending on the case an A may only be average in one class, whereas a B might be the top grade in a completely different one. Without program-specific information there is no way of interpreting grades.
+
Comparison between programs: how good are the other students in the same program?
How can students from different programs be compared with each other? We use IQ-tests and personality scores to compare the students in different programs.

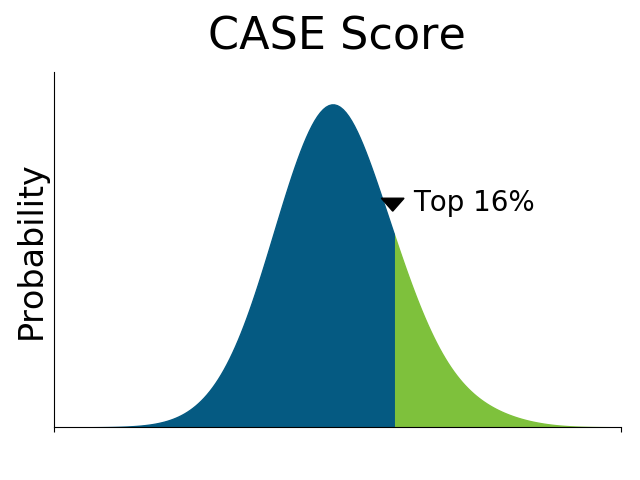
The result: The CASE Score
The CASE algorithm optimizes the weighting of grade distributions and program rankings. This results in the CASE Score, the ideal tool for fairly assessing university performance.
Employers are recommended to take subject- and school-specifc grading practices into consideration when evaluating grades. That is the only way to get an informative idea of the competitiveness of an applicant.
German Science Council, 2012
Page 9, Paragraph 1, Drs. 2627-12, Hamburg 09.11.2012
CASE offers a variety of insights
The analysis produced by CASE has two different levels of detail.
Detailed Analysis
For an in-depth analysis you get a highly detailed report for every individual applicant. Here you can get precise information about where the applicant's GPA stands relative to her peers in the same combination of university, program, degree, and year. Furthermore you get a precise comparison of the applicant's CASE Score relative to all students in the same subject area and country.
+
Overview
You receive an overview of the applicants that our algorithm has determined to be the most promising. All applicants are compared using a standardized scale - the CASE Score. This overview can be used as a first step in evaluating candidates, especially when there is a high volume of applications.
Try CASE today!
Contact us if you have any questions, or register below case-score.de
Contact Contact Register Now Register NowScientific Methods
CASE can currently analyze degrees from Germany, Portugal, Spain, Italy, India, China, US and the UK . Our statistical analysis adds an objective metric to the other measures which are part of a comprehensive screening process. Our rigorous statistical approach helps you to achieve the most precise and least-biased evaluation possible.
CASE uses state-of-the-art econometric approaches to combine a multitude of data sources. This serves as the basis for the analysis of the degree and GPA of a particular applicant. Our methodology differentiates between different universities, areas of study, types of degree, and the year of graduation .
We use this data to generate a comparable CASE Score in a two-step process: first we compare the GPA of an applicant with the distribution of final grades at the same university with the particular combination of field of study, year, and level of degree. The relative position of the applicant is then combined with information about the competitiveness of the particular program they were in. The relative weighting of these factors depends on, among other inputs, the steadily growing body of proprietary CASE data - at the moment this includes more than 500,000 grade distributions and surveys of more than 300,000 students . The CASE algorithm was constructed based on this data, using data of hundreds of thousands of students.